Was pointed to this standard test of executive function (or at least one’s experience of it) called the ESQ-R, the “Executive Skills Questionnaire, Revised”. Always one to see what these self-reporting tools say about by neurodivergence, I took the test here.
No idea as to the test’s ultimate validity but this tracks:
Ed Zitron is an extraordinary writer, who I just discovered via (I have no idea which app, email, or newsletter) but here are a couple of his stories to make your internet-loving heart burn with rage:
The Man Who Killed Google Search – I can remember the cramped shared office I was in when I first tried Google to search the internet and my mind was blown. Ed’s story is heartbreaking. – Steve
They’re Looting the Internet – quote from the previous link but fits here: “search is getting too close to the money”
Went to the theater last night with my girlfriend(😁 👋), like a real adult.
Except it was a shockingly hilarious parody puppet show version of The princess Bride (By S. Morgenstern) by the All Puppet Players, complete with alcohol, musical numbers, 4th wall breaking, flubs, ad-libs and improv.
And I will never hear the lines “I’m going to do him left handed… if I use my right it’s over too quickly!” the same again (Vizzini the puppet: “We didn’t change those lines – at all!!)
Guess it’s time to revisit the blog engine here. I wrote Goldfrog a few years ago and it’s been chugging along on this Digital Ocean instance fairly well, but at the time I had in mind a two-way sync between gitlab, where I maintain a separate repository of my archived content, and the filesystem/db in Goldfrog.
It worked, sort of, for a while, but the deployment on DO is NOT simple to remember, uses Ansible and code from 2 different git repos to set up or update the server, and was just 3 times more clever than it should have been.
I also implemented a flexible/configurable POSSE feature that is supposed to send updates to my mastodon account but … isn’t right now? And the logging setup on the site is abysmal.
I still like parts of my system. If I did it again, I’d still want:
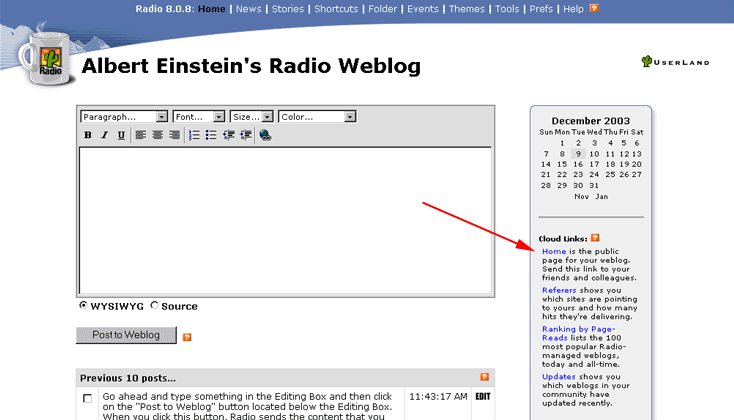
My custom posting UI that works like the ancient Radio Userland sites did: post form at the top of the home page list of posts:
And my version in Goldfrog:
A small web app - not a static site generator
Content stored ultimately as markdown files so they can be stored in git or similar
Content indexed in sqlite for searching. serving various archive pages (tags, etc)
UPDATE: As long as I’m dreaming, I wish it was easier to run a small web app like this off a container. I probably could with Digital Ocean’s app platform, I haven’t looked into it lately, and I’d still have to solve the “index in a sqlite db file” problem.
In the 1960s, Disney discovered and used an incredible “greenscreen” technique to film the Mary Poppins actors in an animated scene, perfectly capturing flowing semi-transparent clothes and motion blur and sharp animated characters. They then lost the tech.
Corridor Crew found out about it, someone figured out how to replicate it, and they worked to demonstrate it. And it’s fucking amazing.
If you’re internet old enough you might remember the Evil Overlord List…
When I’ve captured my adversary and he says, “Look, before you kill me, will you at least tell me what this is all about?” I’ll say, “No.” and shoot him. No, on second thought I’ll shoot him then say “No.”
Having someone tell you “you have this pattern in your life that, if you continue with it, will really hurt me.” Is incredibly hard to hear and incredibly loving to say.
“Curran is 6 days into a drunken binge after being carried kitten-style by that shape-shifted tiger.
He’s been kicked out of 4 taverns for beating other musicians with what was described as “a fucking oboe, and it hurt!” while singing scraps of drinking songs, and two more for storming the stage, yelling “wrong lyrics, you tone-deaf bag of air!”
Some time in the last couple of years I rediscovered [Matt Haughey’s blog]. I subscribed to the RSS feed and am really enjoying his writing again. Bikes, electric vehicles, tech, and general stuff.
Matt’s a great writer and has been doing it for my whole career.